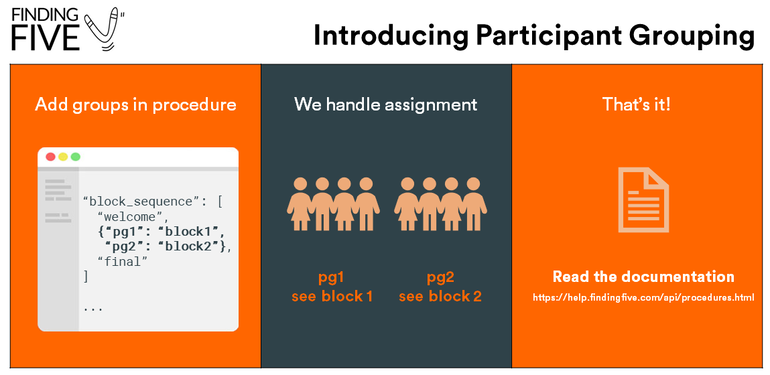
Participant grouping allows you to create different conditions (or “lists”) in your study such that equally-sized groups of participants experience different scenarios during the course of your experiment, regardless of how the participant responds in the study. The assignment of participants to different groups is automatically handled by FindingFive so you don’t need to worry about it.
¶ Example #1: A simple between-subjects experiment
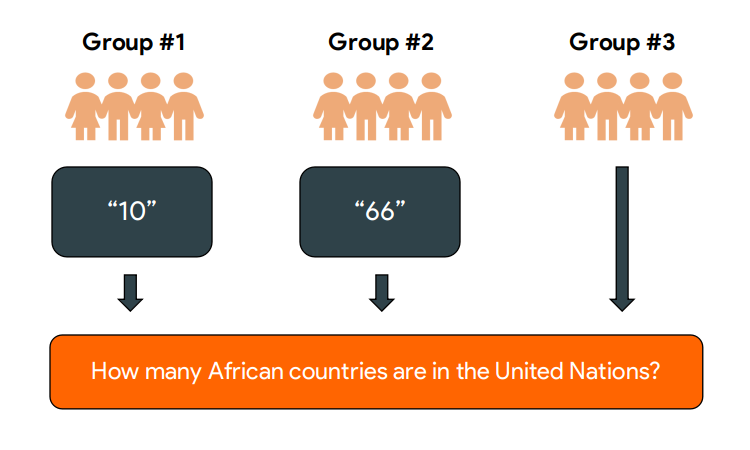
In a simple between-subjects experiment, participants are divided into equally-sized groups, and each group experiences a different set of conditions in the study. For example, in Tversky & Kahneman’s (1974) experiment on psychological anchoring, experimenters spun a wheel that landed on a number between 0 and 100. After seeing this number, participants were asked to guess whether the percentage of countries in Africa that were a part of the United Nations was greater than or less than the wheel’s number. Participants who saw a low number on the wheel guessed that significantly fewer African nations were in the UN than participants who saw a higher number on the wheel.
To create a version of this study in FindingFive, we might imagine three groups of participants. Group 1 is primed with a series of wheel spins that average to a low number, like 10. Group 2 is primed with a series of wheel spins that average to a high number, like 66. Group 3 sees no wheel spins at all. Then all three groups are given the same test prompt, asking them to guess how many African nations are in the UN.
This type of participant grouping occurs in the procedure section of our study, accessed by clicking on the “Procedure” option (next to the “Trial Templates” option) in the upper right side of the Study Specification screen. Importantly, since we want there to be three participant groups, we’ll need to tell FindingFive which parts of our study vary by group by describing three “participant group” dictionaries in our block_sequence. To do this, we’ll edit the procedure of our study to look something like this:
{
"type": "blocking",
"blocks": {
"intro_block": {
// collect demographic information and explain the study, seen by all participants
},
"anchor_block_1": {
// show participants a series of wheel spins that average to the value 10, seen only by Group 1
},
"anchor_block_2": {
// show participants a series of wheel spins that average to the value 66, seen only by Group 2
},
"test_block": {
// test prompt, seen by all participants
}
},
"block_sequence": [
"intro_block",
{"Group1": ["anchor_block_1", "test_block"],
"Group2": ["anchor_block_2", "test_block"],
"Group3": ["test_block"]}
]
}
At the start of a session, participants will be randomly assigned to either Group1, Group2, or Group3. FindingFive’s server handles the assignment automatically to ensure the number of participants in each group will be the same (occasionally, it may not be perfectly balanced due to a couple of really technical reasons; please email us if you are curious about it). The above block_sequence definition will ensure that one third of participants will be presented with intro_block, anchor_block_1, then test_block, one third of participants will be presented with intro_block, anchor_block_2, then test_block, and one third of participants will be presented with intro_block then test_block only.
Note that because there is no participant grouping for the content and sequencing of the intro_block, we don’t need to include it in the list of participant group dictionaries. When the block_sequence is a list consisting of a mixture of block names and participant group dictionaries, blocks outside participant group dictionaries will be presented to all participants, and each participant group will experience their own sequence of blocks as specified in the dictionaries.
¶ Example #2: Counterbalancing the order of blocks in an experiment
Particularly for within-subjects studies, researchers should be careful to control the sequence in which study elements are presented to participants in order to rule out possible order effects. For some situations, the most logical way to handle order effects is at the stimulus– or trial-level, by setting the stimulus_pattern of a trial_template to random, or by defining the pattern of a block to randomize_trials (see the Study Specification Grammar reference sections on the definition of a block and stimulus patterns for more information).
However, there are other times when it makes the most sense to counterbalance the presentation of blocks across multiple participant groups. For a study with two blocks whose presentation order should be counterbalanced, this is easily achieved by defining two participant groups in our procedure:
{
"type": "blocking",
"blocks": {
"block1": {
// insert your block1 definition
},
"block2": {
// insert your block2 definition
}
},
"block_sequence": [
{"Group1": ["block1", "block2"],
"Group2": ["block2", "block1"]}
]
}
¶ “Roundabout” Assignment
The assignment of participants to participant groups is based the “roundabout” method. For example, if you have four participant groups A, B, C, and D, then participants will be assigned to groups in a sequential pattern ABCDABCD instead of fulfilling a single group first, like AABBCCDD. This “roundabout” method ensures that participant assignment will be as evenly as possible, especially when the number of participants recruited ends up being less than originally expected.
¶ Preview a study with multiple participant groups
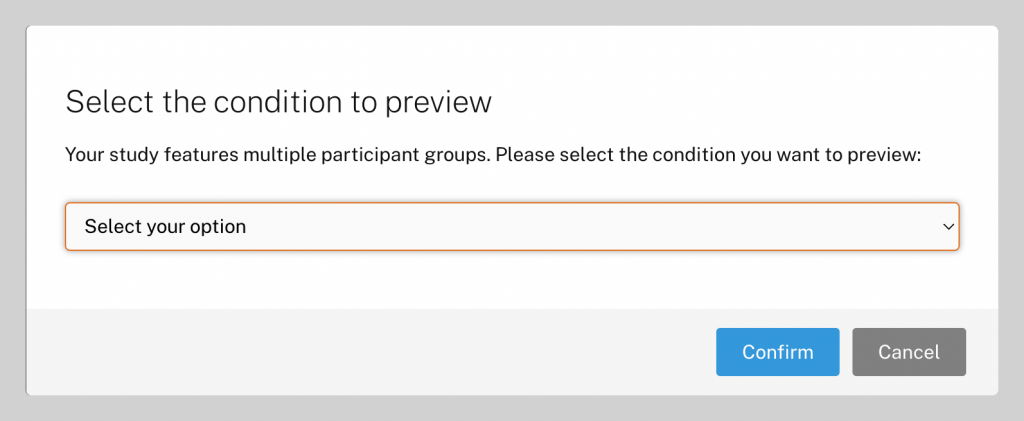
When a study contains multiple participant groups, we have essentially created different versions of the same study. Researchers may want to check out each version to ensure they work correctly before sending the study to participants. FindingFive lets researchers do this easily by prompting researchers to select the version they wish to preview:
¶
For more technical details about participant grouping, check out the Block Sequence section of the FindingFive grammar documentation.
If you have questions about this post or how to create multiple conditions by using participant groups in FindingFive, please don’t hesitate to contact us at [email protected].